Nouvelles specs pour wikitty publication sync

Bonjour, Voici les changements dans les specs en considérant que maintenant il n'y a plus qu'une seule opération de synchronisation entre différents service de wikitty. Il y aura je pense à rajouter des choses dans la définition du wikitty service file system. Manoël.

On Thu, 14 Apr 2011 15:07:22 +0200 Manoël <manoel.fortun@gmail.com> wrote: ...
A ces objets wikitty on associe un wikittyLabel, c'est un objet qui peut contenir un ensemble de label différent, un label par exemple "src.org.chorem.entities" sert ici pour contenir le chemin menant au fichier sur le file system. Un wikitty peut avoir un certain nombre de label, pour les wikittyPub celà indiquera qu'ils appartiennent à plusieurs arborescences.
Bon, plus on avance et plus je vois de problème à l'utilisation de label :(. Par exemple si un PubText a 3 label, lorsqu'il arrive en FS, il n'aura plus que son Path et donc 1 label :(. Or les labels sont stockés dans le wikitty et non l'inverse. L'autre soucis, est si l'on appelle plusieurs PubText avec le meme nom (ils auront un id different mais vu qu'on les references tous avec leur nom, on ne pourra que difficilement avoir plusieurs applis sur le meme WS, il risque d'y avoir rapidement des objets avec les memes noms :( Si on prend une autre solution comme l'utilisation de TreeNode, on a plus le probleme de devoir conserver tous les labels d'un wikitty lorsqu'on le met en FS, car au contraire des Labels, les TreeNode on leur propre Wikitty et contiennent les Ids des Wikitties vers lequel il pointe. Mais pour le clash entre nom d'objet ca n'apporte rien. A moins de devoir donner le chemin complet a chaque fois ce qui serait penible :(. Et surtout on pourrait faire la même chose avec les labels. Mais il nous reste encore une solution :), les WikittyGroup. Qui permettent de rassembler des Wikitty, mais on une vie a eux (ils existent en propre au contraire des Label, et sont moins complexes a gérer/indexer que les TreeNode. Mais leur utilisation actuellement est plutot pour des Group de user, mais on doit pouvoir les reutiliser (a verifier) Faire le remplacement des Labels par des groups ne doit pas être trop dur, donc pour l'instant on change pas, pour que ca mûrisse et voir si on arrive pas a trouver une solution tout de meme avec les Labels, mais prévoir durant le codage que les Labels pourrait etre autre chose. Donc pour le clash de nom, la seul solution que je vois, est: - on met un nom simple, la recherche se fait dans le meme espace que le wikitty courant (donc dans le criteria de facon automatique on ajoute "AND label=xxxxx", ce qui serait moins facile si l'on utilise des groups :(, puisqu'il faudra faire une jointure et en wikitty ca fait 2 requetes) - on met un nom avec un path, la recherche se fait avec label + id (exemple de syntaxe: org.chorem.gepeto.ui#Home) D'ailleurs pour le problème de Label, peut-etre que lorsqu'on renvoi un PubText on ne synchronise que les info de cette extension et pas de l'extension label (on conserve toutes les autres extensions du Wikitty telle qu'elles sont). Par contre on ajoute toujours notre Label dans le champs des Labels (vu que c'est un Set, ca pose pas de probleme). Comme ca si une autre appli a supprimé ce PubText (suppression de son label), on ne le remettra pas, vu qu'on ne fait qu'ajouter le notre. ...
On conservera trace ausi dans ce même fichier de propriété du label courant, permettant de ne pas faire d'opération "complexes" et pénible sur les noms de fichier afin de retrouver le label de travail.
Je ne suis toujours pas d'accord avec ca. Pour moi on ne conserve pas le Label, on le reconstruit au besoin grace au Path sur le FS, car sinon on a une info conservée de deux façon différente et ce n'est jamais un bonne idée.
On distinguera deux fichiers de propriétés pour les informations un qui conservera
Pourquoi ne pas en faire qu'un seul ? id.UUID=fichier.txt version.fichier.txt=numVer checksum.fichier.txt=checksum Je prefaire prefixé par version et checksum que suffixé Apres je ne sais pas ce qui est mieux ce qui est au dessus ou id.fichier.txt=UUID version.UUID=numVer checksum.UUID=checksum Ca depend des demandes qu'on fait sur fichier. C'est peut-etre encore autre chsoe
meta.properties:
script.js.version=numéroVersion7 scripttut.js.version=numéroVersion image.png.version=numéroVersion current.label=racine script.js.checksum= checksum scripttut.js.checksum= checksum image.png.checksum= checksum
id.properties:
uubdazudba=image.png 11daz5facz=scripttut.js jbdub1dza8=script.js
...
Wikitty Service File System ---------------------------
Un tel service devra fournir les méthodes suivantes les méthodes de sauvegarde des wikitty, de restauration, ainsi qu'un certain nombre de fonctionnalités concernant les recherches de wikitty.
Ce service, ne gere que des WikittyPubXXX et lorsqu'on fait un find et qu'il detecte de nouveau fichier, il leur assigne un Id. ps: Il manque le pourquoi de cette nouvelle approche (completement universelle, peut servir pour faire de la syncrho entre 2 WS normaux, comme pour une synchro avec le FS pour les developpeurs). Pour les tests, on peut meme faire des tests avec les WS existant sans encore coder le WSFS. -- Benjamin POUSSIN -------------------- tél: +33 (0) 2 40 50 29 28 email: poussin@codelutin.com http://www.codelutin.com
Le 14/04/2011 18:59, Benjamin POUSSIN a écrit : Je répondrais plus tard sur les labels.
On conservera trace ausi dans ce même fichier de propriété du label courant, permettant de ne pas faire d'opération "complexes" et pénible sur les noms de fichier afin de retrouver le label de travail. Je ne suis toujours pas d'accord avec ca. Pour moi on ne conserve pas le Label, on le reconstruit au besoin grace au Path sur le FS, car sinon on a une info conservée de deux façon différente et ce n'est jamais un bonne idée.
Disons que le problème de ne pas le stocker, c'est qu'après il faut aller remonter dans l'arborescence, chercher le premier fichier .wp pour commencer à reconstruire le label. Et en plus avec cette nouvelle version de sync on ne va plus sauvegarder l'adresse original du wikitty service d'où viennent les wikitty, ça n'a plus de sens, donc on n'a plus de moyen évident et instantanné de savoir si c'est la racine du projet wikitty. Donc c'est pour ça que je voulais avoir l'information directement disponible dans le fichier de propriétés.
On distinguera deux fichiers de propriétés pour les informations un qui conservera Pourquoi ne pas en faire qu'un seul ?
Pour une raison très simple en fait, si je conserve les couples id/file dans un fichier de propriété, je peut compter directement tous les fichiers que je suis censé avoir, détecter les nouveaux fichiers. En faisant propriété.keySet() j'obtiens directement tous les ids des wikittys, les ids ne sont pas perdu au milieu des autres propriétés donc pas besoin de faire un traitement pour obtenir les ids quand c'est seulement eux que je veux.
id.UUID=fichier.txt version.fichier.txt=numVer checksum.fichier.txt=checksum
Je prefaire prefixé par version et checksum que suffixé
Apres je ne sais pas ce qui est mieux ce qui est au dessus ou
id.fichier.txt=UUID version.UUID=numVer checksum.UUID=checksum
Ca depend des demandes qu'on fait sur fichier. C'est peut-etre encore autre chsoe
Pour le préfix/suffix, personnellement peu m'importe, donc on va préfixé si tu préfère. Après je m'étais posé la question de l'ordre du couple id/file, avec la solution de deux fichiers de propriétés je faisais les deux, id/file dans celui des id et file/id dans l'autre, finalement j'ai enlevé le second ne lui trouvant plus d'utilité. J'avais pensé à mettre le tout dans une bidimap, mais le risque était que en chargeant l'ensemble des couples id/file je me retrouve à perdre des informations si plusieurs fichiers de l'arborescence possédaient le même nom.
...
Wikitty Service File System ---------------------------
Un tel service devra fournir les méthodes suivantes les méthodes de sauvegarde des wikitty, de restauration, ainsi qu'un certain nombre de fonctionnalités concernant les recherches de wikitty. Ce service, ne gere que des WikittyPubXXX et lorsqu'on fait un find et qu'il detecte de nouveau fichier, il leur assigne un Id.
ps: Il manque le pourquoi de cette nouvelle approche (completement universelle, peut servir pour faire de la syncrho entre 2 WS normaux, comme pour une synchro avec le FS pour les developpeurs). Pour les tests, on peut meme faire des tests avec les WS existant sans encore coder le WSFS.
Je corrigerais ça pour la prochaine version des specs, enfin quand on aura un peu plus raffinés cette version.
Voilà les corrections que j'ai apporté aux specs en fonction de ce qui est revenu des discussions et de l'implémentation actuel. Manoël,
Bonjour, Comme je le soulignais hier pendant la réunion, où j'ai présenté le module sync de wikitty publication, le mécanisme de sauvegarde des wikitty au niveau des versions me pose problème. Puisque un wikitty service qui reçoit un wikitty qu'il ne possède pas dans sa base, l'enregistre en tant que version 1.0 quelque soit la version du wikitty qu'il reçoit. Pour moi, le wikitty service à partir du moment où la version du wikitty qu'il reçoit est supérieur à celle qu'il à en base, il doit enregistrer ce wikitty dans sa base avec le numéro de version du wikitty (voir incrémenter la version majeur si la version mineur n'est pas de 0), mais surtout pas continuer à incrémenter la version de son wikitty correspondant dans sa base. Si il possède un wikitty en version 1.0 et qu'on lui demande de sauvegarder le même wikitty mais en version 5.0, il doit l'enregistrer en 5.0 et pas en 2.0. Après je ne sais pas si ça impact énormément le reste des projets liés ou non, mais pour le module de sync de publication ce mécanisme est handicapant. Manoël.
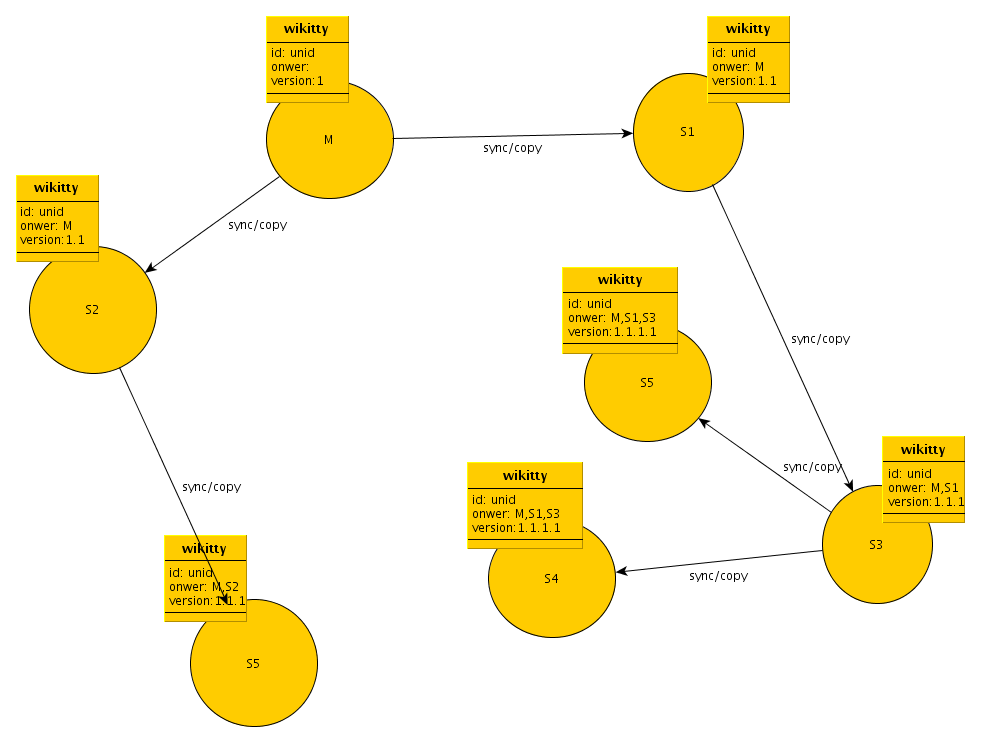
Bonjour, Comme je le soulignais la gestion actuelle des versions des wikitty par les services est problématique pour les synchronisations entre différent wikitty service. Benjamin à évoqué une solution avec un nouveau champ dans les wikitty avec une notion de propriétaire de wikitty. Voici la spec en rst sur ce que j'ai "exploré" sur le sujet, je ne pense pas avoir oublié de cas. Par contre il y a une image pour que les explications soient plus clair, je sais pas si je dois envoyer le tout sous un format autre que rst, donc dans le doute je joint le rst et l'image. Si besoin je ferais un pdf avec latex. Manoël.
{kind=link}
On Wed, 27 Apr 2011 15:09:55 +0200 Manoël Fortun <manoel.fortun@gmail.com> wrote: Salut, Sur papier, cette solution me parrait bonne, a voir en pratique si elle tien le choc. Par contre, je n'aime pas owner (on confond avec l'utilisateur qui a créer le wikitty). Je préfère: - serverPath - serverOwner - serverSource avec une préférence pour le 1er choix
Le seul soucis visible de cette solution pour le moment, est lors de la disparition d'un pair en début de chaine qui laisserais plusieurs pair fils au même niveau de owner, avec la même version majeur issu
Je pense que si ce soucis arrive, il faudra le traiter applicativement avec un choix utilisateur. Par contre tu n'as pas traité le cas, ou s4 envoi le wikitty a s2 que fait s2 dans ce cas ? sachant qu'on aura: m:s1:s3:s4 qui voudra aller sur m:s2 Peut-être tout simplement l'accepter sur la version m est compatible et l'objet devient m:s2 (avec la version s2 incrémentée) Donc peut-être que l'algo ou le serveur se recherche dans le path, au lieu de se rechercher, on recherche le dernier serveur du wikitty local dans le wikitty qui arrive. Cela permet peut-etre de regler tous les cas (a reflechir) -- Benjamin POUSSIN -------------------- tél: +33 (0) 2 40 50 29 28 email: poussin@codelutin.com http://www.codelutin.com
Par contre, je n'aime pas owner (on confond avec l'utilisateur qui a
créer le wikitty).
Je préfère: - serverPath - serverOwner - serverSource
avec une préférence pour le 1er choix Effectivement peut il y avoir confusion, pour ma part aucune préférence, je changerais pour serverPath, puisque c'est une sorte de chemin.
Le seul soucis visible de cette solution pour le moment, est lors de la disparition d'un pair en début de chaine qui laisserais plusieurs pair fils au même niveau de owner, avec la même version majeur issu Je pense que si ce soucis arrive, il faudra le traiter applicativement avec un choix utilisateur.
Par contre tu n'as pas traité le cas, ou s4 envoi le wikitty a s2 que fait s2 dans ce cas ?
sachant qu'on aura: m:s1:s3:s4 qui voudra aller sur m:s2
Peut-être tout simplement l'accepter sur la version m est compatible et l'objet devient m:s2 (avec la version s2 incrémentée) Pour moi dans un cas comme celui ci, si la version M est plus récente pour le wikitty qui viens de s4, alors on écrasera la version sur s2 et le wikitty aura le serverPath: m:s1:s3:s4.
Après dans le cas contraire il faudrait que la synchronisation vienne de M pour "mettre à jour" le wikitty sur S2.
Donc peut-être que l'algo ou le serveur se recherche dans le path, au lieu de se rechercher, on recherche le dernier serveur du wikitty local dans le wikitty qui arrive. Cela permet peut-etre de regler tous les cas (a reflechir)
C'est peut être mal explicité dans mes specs mais pour moi c'est ce que l'on fait plus ou moins déja, quand on compare les versions on compare les versions tronquées mais ces versions sont tronquées au niveau des versions mineurs, pas des versions majeur. Par exemple si s1 possède un wikitty en 3.1(path: m) et que il reçoit de s4 un wikitty en version 2.2.3.5 (path: m:s1:s3) on comparera les version 3.1 à 2.2, et donc le wikitty sur s1 ne sera pas modifié. Quoi qu'il arrive celà ne règle pas le problème de wikitty dont le père à disparut, qu'il faudra "merger" à la main ou du moins laisser le choix à l'utilisateur.
participants (3)
-
 Benjamin POUSSIN
Benjamin POUSSIN -
 Manoël
Manoël -
Manoël Fortun